ゲームの面白さのデータベース作りは続けていく方針
意外と楽しい
パターンの選択はふと思いついたやつ
2018年9月22日土曜日
2018年9月21日金曜日
ゲームの面白さをパターン化したい
新しいゲームをsteamで探す趣味があるわけですが、探すときに無意識的にやっている行動が
1.好きなゲームを考察して、抽象化、要素を取り出す
2.抽象化された中で、自分の好きな要素は何か考える
3.その要素を持っていそうなゲームを探す
と、まあこんな感じ。
具体的に言うと
「FNAFシリーズ楽しいな」
↓抽象化、要素の分解
「ストーリー」「リアルタイムな処理」「優先順位の決定」「忙しい操作」...
↓自分が好きな要素を考える
「リアルタイム処理」「優先順位の決定」あたりが好きそう...
↓似たゲームを探す
Lobotomy Corporation!
これ、意識的にやればなんかいい感じになるのでは?
特に、抽象化した概念は、しっかり記録して、考察すればなんかもっといい感じの情報になりそう。
記録するならば、記録する方法についても考えないと。
ここで思い出したのが、プロセスパターンって言葉。
なんか、ソフトウェアエンジニアリングの勉強をしたときに聞いたことある気がする。
調べてみるとアンブラー(Ambler)さんって人がうまくいったプロセスをテンプレート化しましょうってことで、テンプレートの書式を作ったっぽい。
(プロセスという考え方は使いこなすと便利なんですが、ちゃんと書くとなると難しい...)
アンブラーさんは的にはテンプレートに以下の項目を定義してます。
・パターン名
・目的
・型
・初期コンテスト
・問題
・解決策
・問題解決後の状況
・関連パターン
・事例
個人的には関連パターンの項目がよきよき。
共起するパターンなんかをメモできると、考察に良さそう。
とりあえず、ゲームで使えそうな感じに直してみませう。
型は、いろいろ事例を集めてからじゃないと難しいからとりあえず抜きます。
プロセスは問題解決のためにあるけど、自分が欲しい情報はそういうわけでもないし、とりあえずなくてもよさそう?
どういうところを面白く感じるか、そのパターンを使った時のデメリットは欲しいなぁ。
事例には、実際にそのパターンを感じたゲームを入れて...っとこんな感じでしょうか?
・パターン名
・パターンの特性
・面白さ
・デメリット
・関連パターン
・事例
とりあえず、いくつかパターンを生成してみます。
こういうモデルづくりは、最初から完璧なものを作ろうと思わず、いろいろやってみるのがコツだったり。
<パターン名>
4人協力型Coop・箱庭型
<パターンの特性>
協力者と一つのステージで協力してNPCボスと戦う。
<面白さ>
1つの目的に対して協力して達成する一体感を感じられる。
洗練されたチームワークは高揚感を感じる。
<デメリット>
ソロとのバランスが難しい。
協力者とのゲームの進行度の差。
難しすぎると、大縄跳び化する。
<関連パターン>
大縄跳び化
<事例>
モンスターハンター
ゴッドイーター
<パターン名>
大縄跳び
<パターンの特性>
複数人で、高難易度Coopを行うときに発生する。
全員が、ギミックを理解し、完璧に対処することが求められる。
<面白さ>
洗練されたチームワークは高揚感を感じる。
達成感が強い。
<デメリット>
個性が出しずらい。
最適な行動が求められ、それ以外が許されなくなる。
初見の人がとっつきにくい。
<関連パターン>
<事例>
FF14・グラブル
<パターン名>
高難易度
<パターン特性>
クリアが難しい
<面白さ>
トライ&エラーに成長を感じられる
達成感が強い
<デメリット>
人を選ぶ
最後までプレイできる人が少ない
できないと悲しくなる
<関連パターン>
理不尽
ロスト
<事例>
ダークソウル・NINJA GAIDEN・getting over it
<パターン名>
ローグ
<パターン特性>
ランダムに生成されたステージを、初期状態から始めるゲームジャンル。
<メリット>
毎回新しい展開が得られるため、繰り返し遊びやすい
知識が蓄積することで成長を感じる
<デメリット>
高難易度になりやすい
運に左右されやすく、理不尽を感じる可能性がある
リセットが増える
<関連パターン>
高難易度
理不尽
<事例>
風来のシレン・Slay the Spire
とりあえず、4つほど書いてみた。
結構いい感じなのでは?
再利用性も結構良さそうだし。
例えば、自分は「大縄跳び」結構好きだなぁと感じたら、そういう要素のゲームを探してみたりできそうだし。
ゲーム作ろうってなった時、どういう体験を与えたいかを考えて、それに合うメリットを持ったパターンを探すってこともできそうだし。
パターン名はできるだけ抽象度とか、効果の範囲とかが違うものを選んでみた。
情報を蓄積していけば型として分類できるかも。
事例は2つくらい挙げたけど、もっと増やしてもいいなぁ。
あと、これ一つ一つの記事にして、関連パターンをリンクでつなぐといい感じかも。
暇なときに増やしていこう。。。
1.好きなゲームを考察して、抽象化、要素を取り出す
2.抽象化された中で、自分の好きな要素は何か考える
3.その要素を持っていそうなゲームを探す
と、まあこんな感じ。
具体的に言うと
「FNAFシリーズ楽しいな」
↓抽象化、要素の分解
「ストーリー」「リアルタイムな処理」「優先順位の決定」「忙しい操作」...
↓自分が好きな要素を考える
「リアルタイム処理」「優先順位の決定」あたりが好きそう...
↓似たゲームを探す
Lobotomy Corporation!
これ、意識的にやればなんかいい感じになるのでは?
特に、抽象化した概念は、しっかり記録して、考察すればなんかもっといい感じの情報になりそう。
記録するならば、記録する方法についても考えないと。
ここで思い出したのが、プロセスパターンって言葉。
なんか、ソフトウェアエンジニアリングの勉強をしたときに聞いたことある気がする。
調べてみるとアンブラー(Ambler)さんって人がうまくいったプロセスをテンプレート化しましょうってことで、テンプレートの書式を作ったっぽい。
(プロセスという考え方は使いこなすと便利なんですが、ちゃんと書くとなると難しい...)
アンブラーさんは的にはテンプレートに以下の項目を定義してます。
・パターン名
・目的
・型
・初期コンテスト
・問題
・解決策
・問題解決後の状況
・関連パターン
・事例
個人的には関連パターンの項目がよきよき。
共起するパターンなんかをメモできると、考察に良さそう。
とりあえず、ゲームで使えそうな感じに直してみませう。
型は、いろいろ事例を集めてからじゃないと難しいからとりあえず抜きます。
プロセスは問題解決のためにあるけど、自分が欲しい情報はそういうわけでもないし、とりあえずなくてもよさそう?
どういうところを面白く感じるか、そのパターンを使った時のデメリットは欲しいなぁ。
事例には、実際にそのパターンを感じたゲームを入れて...っとこんな感じでしょうか?
・パターン名
・パターンの特性
・面白さ
・デメリット
・関連パターン
・事例
とりあえず、いくつかパターンを生成してみます。
こういうモデルづくりは、最初から完璧なものを作ろうと思わず、いろいろやってみるのがコツだったり。
<パターン名>
4人協力型Coop・箱庭型
<パターンの特性>
協力者と一つのステージで協力してNPCボスと戦う。
<面白さ>
1つの目的に対して協力して達成する一体感を感じられる。
洗練されたチームワークは高揚感を感じる。
<デメリット>
ソロとのバランスが難しい。
協力者とのゲームの進行度の差。
難しすぎると、大縄跳び化する。
<関連パターン>
大縄跳び化
<事例>
モンスターハンター
ゴッドイーター
<パターン名>
大縄跳び
<パターンの特性>
複数人で、高難易度Coopを行うときに発生する。
全員が、ギミックを理解し、完璧に対処することが求められる。
<面白さ>
洗練されたチームワークは高揚感を感じる。
達成感が強い。
<デメリット>
個性が出しずらい。
最適な行動が求められ、それ以外が許されなくなる。
初見の人がとっつきにくい。
<関連パターン>
<事例>
FF14・グラブル
<パターン名>
高難易度
<パターン特性>
クリアが難しい
<面白さ>
トライ&エラーに成長を感じられる
達成感が強い
<デメリット>
人を選ぶ
最後までプレイできる人が少ない
できないと悲しくなる
<関連パターン>
理不尽
ロスト
<事例>
ダークソウル・NINJA GAIDEN・getting over it
<パターン名>
ローグ
<パターン特性>
ランダムに生成されたステージを、初期状態から始めるゲームジャンル。
<メリット>
毎回新しい展開が得られるため、繰り返し遊びやすい
知識が蓄積することで成長を感じる
<デメリット>
高難易度になりやすい
運に左右されやすく、理不尽を感じる可能性がある
リセットが増える
<関連パターン>
高難易度
理不尽
<事例>
風来のシレン・Slay the Spire
とりあえず、4つほど書いてみた。
結構いい感じなのでは?
再利用性も結構良さそうだし。
例えば、自分は「大縄跳び」結構好きだなぁと感じたら、そういう要素のゲームを探してみたりできそうだし。
ゲーム作ろうってなった時、どういう体験を与えたいかを考えて、それに合うメリットを持ったパターンを探すってこともできそうだし。
パターン名はできるだけ抽象度とか、効果の範囲とかが違うものを選んでみた。
情報を蓄積していけば型として分類できるかも。
事例は2つくらい挙げたけど、もっと増やしてもいいなぁ。
あと、これ一つ一つの記事にして、関連パターンをリンクでつなぐといい感じかも。
暇なときに増やしていこう。。。
2018年9月15日土曜日
Pythonでヤフーニュースをスクレイピング
最近スクレイピングの勉強しているから、目標を立てて使ってみる。
スクレイピングとは、ウェブサイトから情報を抽出するコンピュータソフトウェア技術のこと。らしいです。Wikipediaによると。
というわけで、情報集めを自動化できるようになりたいなぁってことで、練習練習。
目標:yahooニュースから更新されている記事の本文を取得する。
今回使うのはseleniumですね。ブラウザを自動操作できるテストツールらしいです。
水銀中毒に効きそうないい名前ですね!
pip install seleniumでインストールして、動かすためのブラウザも用意します。
このページからchromedriver.exeをダウンロード、カレントディレクトリーに置いておきます。

まずは必要そうなライブラリーをimportして、googlechromeでヤフーニュースのゲームタグを開きました。
"https://news.yahoo.co.jp/hl?c=game"
URLを変えれば好きなページでスクレイピングできます。
さて、開いたページから欲しそうな情報をどんどん引き抜いていきす。
とりあえず、記事のタイトルとURLが欲しいかな?
欲しい要素を右クリックして、検証を選んで
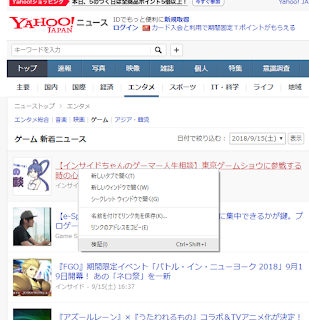
これだって感じのhtmlの行を見つけたら右クリックして、CSSセレクタをゲット。
CSSセレクタは要素を選択するための条件式みたいなものっぽい。
GoogleChromeは、html読まなくても、見つけられるから便利便利。

URL
#main > div.epCategory > div > ul > li:nth-child(1) > a
タイトル
#main > div.epCategory > div > ul > li:nth-child(1) > a > div > div.listFeedWrapCont > dl > dt
こんな感じのCSSセレクタがゲットできました。
find_elements_by_css_selector()という関数で、htmlを手に入れられるのでこんな感じで。

これ、取り出す要素が一つでもリストで帰ってくるのか...
li:nth-child(1)の1って数字が記事の1番目を指している気がするので、ここを変えれば全部の記事のタイトルとURLが手に入れられる気がする。
なんか、参考書で似たようなことをやるときにnth-of-type(n)って表記していたから、数字の代わりにnを入れれば、全部の要素を取り出せそう。

いいかんじ
このURLにをgooglechromeで開いて、記事の本文を見つければよさそう。
さっきやったことを繰り返して。

手に入れたURLをdriver.get()でページを開く。
タイトルと本文をリストに追加して、ページの情報をゲットです。

やっとできた。
<おまけ>
・前回起動したときなかった記事だけ欲しい
・記事をデータベース化して保存しておきたい
・ボイスロイドに読ませたい
って感じでコーディング
スクレイピングとは、ウェブサイトから情報を抽出するコンピュータソフトウェア技術のこと。らしいです。Wikipediaによると。
というわけで、情報集めを自動化できるようになりたいなぁってことで、練習練習。
目標:yahooニュースから更新されている記事の本文を取得する。
今回使うのはseleniumですね。ブラウザを自動操作できるテストツールらしいです。
水銀中毒に効きそうないい名前ですね!
pip install seleniumでインストールして、動かすためのブラウザも用意します。
このページからchromedriver.exeをダウンロード、カレントディレクトリーに置いておきます。

まずは必要そうなライブラリーをimportして、googlechromeでヤフーニュースのゲームタグを開きました。
"https://news.yahoo.co.jp/hl?c=game"
URLを変えれば好きなページでスクレイピングできます。
さて、開いたページから欲しそうな情報をどんどん引き抜いていきす。
とりあえず、記事のタイトルとURLが欲しいかな?
欲しい要素を右クリックして、検証を選んで

これだって感じのhtmlの行を見つけたら右クリックして、CSSセレクタをゲット。
CSSセレクタは要素を選択するための条件式みたいなものっぽい。
GoogleChromeは、html読まなくても、見つけられるから便利便利。

URL
#main > div.epCategory > div > ul > li:nth-child(1) > a
タイトル
#main > div.epCategory > div > ul > li:nth-child(1) > a > div > div.listFeedWrapCont > dl > dt
こんな感じのCSSセレクタがゲットできました。
find_elements_by_css_selector()という関数で、htmlを手に入れられるのでこんな感じで。

これ、取り出す要素が一つでもリストで帰ってくるのか...
li:nth-child(1)の1って数字が記事の1番目を指している気がするので、ここを変えれば全部の記事のタイトルとURLが手に入れられる気がする。
なんか、参考書で似たようなことをやるときにnth-of-type(n)って表記していたから、数字の代わりにnを入れれば、全部の要素を取り出せそう。

いいかんじ
このURLにをgooglechromeで開いて、記事の本文を見つければよさそう。
さっきやったことを繰り返して。
手に入れたURLをdriver.get()でページを開く。
タイトルと本文をリストに追加して、ページの情報をゲットです。

やっとできた。
<おまけ>
・前回起動したときなかった記事だけ欲しい
・記事をデータベース化して保存しておきたい
・ボイスロイドに読ませたい
って感じでコーディング
2018年9月8日土曜日
できるだけ簡単にPythonで音声認識してVOICEROIDにしゃべらせる
Five Night at Freddy'sの2と3攻略してたらなんかすごい時間食った。
Five Night at Freddy's 4がもっと怖くなかったら4まで一気にクリアてたかも。
実際は怖すぎてできないけど。
今回は「Pythonで音声認識してVOICEROIDにしゃべらせる」ところまでやりましょう。
Google Cloud Speech APIなどは自分で設定すると難しいので、サポートしてくれるライブラリー、SpeechRecognitionを使います。
SpeechRecognition
オンラインとオフラインの複数のエンジンとAPIをサポートし、音声認識を実行するためのライブラリです。
インストールは
pip install SpeechRecognition
で問題ないです。
現在version3.8.1ではpython3.7には対応していないみたいですね。
自分の環境が3.6なので、3.7で確認はしていないです。
まずは、簡単なところで、wavファイルからtextを手に入れるところからやってみます。
import speech_recognition as sr
filename ="sample.wav"
r = sr.Recognizer()
with sr.AudioFile(filename) as source:
audio = r.record(source)
try:
text = "Google Speech Recognition thinks you said " + r.recognize_google(audio, language='ja-JP')
print(text)
except:
pass
こんな感じで問題ないでしょう。
カレントディレクトリーに存在する、wavファイルの名前を入れれば解析してくれます。
戻り値として、音声認識の結果を返してくれます。
これを前回の録音と組み合わせれば、音声認識の完成ですね。
このモジュール、言葉の認識できないとエラーを返すので、しっかりtry処理を行いましょう。
次に、wavファイルを経由しない方法です。
前提として、pyaudioをインストールしてください。
import speech_recognition as sr
r = sr.Recognizer()
with sr.Microphone() as source:
print("何か、話しかけてください")
audio = r.listen(source)
try:
print("Google Speech Recognition thinks you said " + r.recognize_google(audio,language='ja-JP'))
except:
pass
こんな感じでしょうか。結構簡単にできますね。
自分は録音開始時に処理を入れているので前者を使っていますが、基本的にはこちらで問題ないでしょう。
それでは、サクッと組み合わせて「ゆかりねっともどき」を作ってみましょう。
import speech_recognition as sr
import subprocess as sps
r = sr.Recognizer()
with sr.Microphone() as source:
print("何か、話しかけてください")
audio = r.listen(source)
try:
text = r.recognize_google(audio,language='ja-JP')
except:
pass
cmd = 'seikasay.exe -cid ' + "2000" + ' \"' + text + '\"'
sps.call(cmd,shell=True)
完成です。
今回は1回だけ、しゃべったことをボイスロイドにしゃべらせるプログラムですね。
あとは、これをループ処理にしたり、非同期処理にしたりすれば、いいわけです。
それにしても、簡単にできました。ほとんどseikasay.exeやPythonの優秀なモジュールのおかげですね。
Five Night at Freddy's 4がもっと怖くなかったら4まで一気にクリアてたかも。
実際は怖すぎてできないけど。
今回は「Pythonで音声認識してVOICEROIDにしゃべらせる」ところまでやりましょう。
Google Cloud Speech APIなどは自分で設定すると難しいので、サポートしてくれるライブラリー、SpeechRecognitionを使います。
SpeechRecognition
オンラインとオフラインの複数のエンジンとAPIをサポートし、音声認識を実行するためのライブラリです。
インストールは
pip install SpeechRecognition
で問題ないです。
現在version3.8.1ではpython3.7には対応していないみたいですね。
自分の環境が3.6なので、3.7で確認はしていないです。
まずは、簡単なところで、wavファイルからtextを手に入れるところからやってみます。
import speech_recognition as sr
filename ="sample.wav"
r = sr.Recognizer()
with sr.AudioFile(filename) as source:
audio = r.record(source)
try:
text = "Google Speech Recognition thinks you said " + r.recognize_google(audio, language='ja-JP')
print(text)
except:
pass
こんな感じで問題ないでしょう。
カレントディレクトリーに存在する、wavファイルの名前を入れれば解析してくれます。
戻り値として、音声認識の結果を返してくれます。
これを前回の録音と組み合わせれば、音声認識の完成ですね。
このモジュール、言葉の認識できないとエラーを返すので、しっかりtry処理を行いましょう。
次に、wavファイルを経由しない方法です。
前提として、pyaudioをインストールしてください。
import speech_recognition as sr
r = sr.Recognizer()
with sr.Microphone() as source:
print("何か、話しかけてください")
audio = r.listen(source)
try:
print("Google Speech Recognition thinks you said " + r.recognize_google(audio,language='ja-JP'))
except:
pass
こんな感じでしょうか。結構簡単にできますね。
自分は録音開始時に処理を入れているので前者を使っていますが、基本的にはこちらで問題ないでしょう。
それでは、サクッと組み合わせて「ゆかりねっともどき」を作ってみましょう。
import speech_recognition as sr
import subprocess as sps
r = sr.Recognizer()
with sr.Microphone() as source:
print("何か、話しかけてください")
audio = r.listen(source)
try:
text = r.recognize_google(audio,language='ja-JP')
except:
pass
cmd = 'seikasay.exe -cid ' + "2000" + ' \"' + text + '\"'
sps.call(cmd,shell=True)
完成です。
今回は1回だけ、しゃべったことをボイスロイドにしゃべらせるプログラムですね。
あとは、これをループ処理にしたり、非同期処理にしたりすれば、いいわけです。
それにしても、簡単にできました。ほとんどseikasay.exeやPythonの優秀なモジュールのおかげですね。
2018年9月5日水曜日
Pythonでしゃべっているときだけ録音する
VOICEROIDをプログラムに組み込めるようになったわけだし何か作ってみよう!
VOICEROIDをプログラムで動かせる方法を手に入れたわけだけど、どういうときに使うのがいいんだろうか...
しゃべることが決まっているなら、wavファイルにして、再生した方がいいです。
考えてみたところこんなことろかなぁと
1.人が出力する文章
2.自動で生成される文章
1だと、ゆかりねっととか、ブログやネット上の記事をスクレイピングとかでしょうか。
2だと、マルコフ連鎖とか、LSTMとか?
というわけで、まずは前例に倣って「音声認識して、VOICEROIDにしゃべらせる」を目指していこうかと。
流れ的には、録音→解析→VOICEROIDに投げる、の流れですね。
今回は録音できるようにソースコードを書いてみます。
Pythonで音を監視して一定以上の音量を録音する-Qiita
こちらの記事を参考に、
・一定音量を超えたら録音する
・録音状態で一定の音量を下回った時間が1秒を超えたら録音を終了する
を実現できるように少しだけ改良します。
import pyaudio
import wave
import numpy as np
threshold = 0.03
thresholdmin = 0.02
chunk = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 44100
blank = 1
p = pyaudio.PyAudio()
stream = p.open(format = FORMAT, #(1)
channels = CHANNELS,
rate = RATE,
input = True,
frames_per_buffer = chunk
)
sound=[]
while True:
data = stream.read(chunk) #(2)
x = np.frombuffer(data, dtype="int16") / 32768.0
if x.max() > threshold: #(3)
rec = 0
filename = "test.wav"
sound=[]
sound.append(data)
while rec < int(blank * RATE / chunk):
data = stream.read(chunk)
sound.append(data)
x = np.frombuffer(data, dtype="int16") / 32768.0
if x.max() < thresholdmin: #(4)
rec += 1
else:
rec = 0
data = b''.join(sound)
out = wave.open(filename,'w') #(5)
out.setnchannels(CHANNELS)
out.setsampwidth(2)
out.setframerate(RATE)
out.writeframes(data)
out.close()
break
stream.close()
p.terminate()
こんな感じですね。
処理的には
(1)pyaudio.PyAudioのインスタンスstreamを生成
(2)streamのデータを手に入れる
(3)音量を調べて、threshold以上の音量ならばstreamのデータをsoundリストに保存
(4)thresholdmini以下の音量ならばカウントを初めて、1秒超えたらループから抜けるように
(5)wavファイルに保存
と、こんな感じでしょう。
(4)が少し変更した部分ですね。動かしてみて、マイクに話しかけるとtest.wavという音声ファイルができているはずです。
今回はここまでにしましょう。
次は、wavファイルを解析して、日本語にする感じですかね。
実は、「音声認識して、VOICEROIDにしゃべらせる」という、部分はもうずいぶん前にコードを書いて、すでに魔改造まで終わっちゃっているんですよね。
備忘録気分で始めたブログなので、最近やっていることも書きたいのに、たまりにたまったアウトプットしていないソースコードたちががが...
VOICEROIDをプログラムで動かせる方法を手に入れたわけだけど、どういうときに使うのがいいんだろうか...
しゃべることが決まっているなら、wavファイルにして、再生した方がいいです。
考えてみたところこんなことろかなぁと
1.人が出力する文章
2.自動で生成される文章
1だと、ゆかりねっととか、ブログやネット上の記事をスクレイピングとかでしょうか。
2だと、マルコフ連鎖とか、LSTMとか?
というわけで、まずは前例に倣って「音声認識して、VOICEROIDにしゃべらせる」を目指していこうかと。
流れ的には、録音→解析→VOICEROIDに投げる、の流れですね。
今回は録音できるようにソースコードを書いてみます。
Pythonで音を監視して一定以上の音量を録音する-Qiita
こちらの記事を参考に、
・一定音量を超えたら録音する
・録音状態で一定の音量を下回った時間が1秒を超えたら録音を終了する
を実現できるように少しだけ改良します。
import pyaudio
import wave
import numpy as np
threshold = 0.03
thresholdmin = 0.02
chunk = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 44100
blank = 1
p = pyaudio.PyAudio()
stream = p.open(format = FORMAT, #(1)
channels = CHANNELS,
rate = RATE,
input = True,
frames_per_buffer = chunk
)
sound=[]
while True:
data = stream.read(chunk) #(2)
x = np.frombuffer(data, dtype="int16") / 32768.0
if x.max() > threshold: #(3)
rec = 0
filename = "test.wav"
sound=[]
sound.append(data)
while rec < int(blank * RATE / chunk):
data = stream.read(chunk)
sound.append(data)
x = np.frombuffer(data, dtype="int16") / 32768.0
if x.max() < thresholdmin: #(4)
rec += 1
else:
rec = 0
data = b''.join(sound)
out = wave.open(filename,'w') #(5)
out.setnchannels(CHANNELS)
out.setsampwidth(2)
out.setframerate(RATE)
out.writeframes(data)
out.close()
break
stream.close()
p.terminate()
こんな感じですね。
処理的には
(1)pyaudio.PyAudioのインスタンスstreamを生成
(2)streamのデータを手に入れる
(3)音量を調べて、threshold以上の音量ならばstreamのデータをsoundリストに保存
(4)thresholdmini以下の音量ならばカウントを初めて、1秒超えたらループから抜けるように
(5)wavファイルに保存
と、こんな感じでしょう。
(4)が少し変更した部分ですね。動かしてみて、マイクに話しかけるとtest.wavという音声ファイルができているはずです。
今回はここまでにしましょう。
次は、wavファイルを解析して、日本語にする感じですかね。
実は、「音声認識して、VOICEROIDにしゃべらせる」という、部分はもうずいぶん前にコードを書いて、すでに魔改造まで終わっちゃっているんですよね。
備忘録気分で始めたブログなので、最近やっていることも書きたいのに、たまりにたまったアウトプットしていないソースコードたちががが...
2018年9月4日火曜日
2018年9月3日月曜日
登録:
投稿 (Atom)